Управление поисковыми роботами для лучшей индексации и ранжирования
- Сканирование и индексация вкратце Возьмите под свой контроль процесс сканирования и индексации своего...
- Как работает индексирование?
- Как взять под контроль сканирование и индексирование
- Методы контроля сканирования и индексации
- Конечная таблица на сканирование и индексирование
- Директивы роботов
- Канонические URL
- Атрибут Hreflang
- Атрибуты пагинации
- Мобильный атрибут
- Конечная таблица на сканирование и индексирование
- Получить в качестве поисковых систем: поставить себя на их место
- Другие ситуации, в которых Fetch as Googlebot пригодится
- Часто задаваемые вопросы о сканировании и индексации
- 2. Могу ли я замедлить сканеры, когда они сканируют мой сайт?
- 3. Как запретить поисковым системам сканировать веб-сайт или страницу?
- 4. Что означает индексация сайта?
- 5. Является ли мой сайт индексируемым для поисковых систем?
- 6. Как часто Google индексирует мой сайт?
- 7. Сколько времени понадобится Google, чтобы проиндексировать мой новый сайт?
- 8. Как запретить поисковым системам индексировать сайт или страницу?
Сканирование и индексация вкратце
Возьмите под свой контроль процесс сканирования и индексации своего сайта, сообщив свои предпочтения поисковым системам.
Это помогает им понять, на каких частях вашего веб-сайта следует сосредоточиться, а какие - игнорировать. Есть много способов сделать это, поэтому когда использовать какой метод?
В этой статье мы обсудим, когда использовать каждый из этих методов, а также рассмотрим плюсы и минусы.
Поисковые системы сканируют миллиарды страниц каждый день. Но они индексируют меньше страниц, чем это, и они показывают еще меньше страниц в своих результатах. Вы хотите, чтобы ваши страницы были среди них. Итак, как вы контролируете весь этот процесс и повышаете свой рейтинг?
Чтобы ответить на этот вопрос, сначала нам нужно посмотреть, как работает процесс сканирования и индексации. Затем мы обсудим все методы, которые вы можете использовать для управления этим процессом.
Как работает сканирование?
Сканерам поисковых систем поручено находить и сканировать как можно больше URL-адресов. Они делают это, чтобы увидеть, есть ли новый контент там. Эти URL могут быть как новыми, так и теми, о которых они уже знали. Новые URL-адреса обнаруживаются при сканировании уже известных им страниц. После сканирования они передают свои результаты индексатору. Страницы, которые поисковые системы могут сканировать, часто называют сканируемыми .
Как работает индексирование?
Индексаторы получают содержимое URL-адресов от сканеров. Затем индексаторы пытаются разобраться в этом контенте, анализируя его (включая ссылки, если таковые имеются). Индексатор обрабатывает канонизированные URL-адреса и определяет полномочия каждого URL-адреса. Индексатор также определяет, должны ли они индексировать страницу. Страницы, которые поисковые системы могут индексировать, часто называют индексируемыми .
Индексаторы также отображают веб-страницы и выполняют JavaScript. Если это приводит к обнаружению каких-либо ссылок, они возвращаются сканеру.
Как взять под контроль сканирование и индексирование
Возьмите под контроль процесс сканирования и индексации, сделав ваши настройки понятными для поисковых систем. Этим вы поможете им понять, какие разделы вашего сайта наиболее важны для вас.
В этой главе мы рассмотрим все методы и которые использовать когда. Мы также составили таблицу, чтобы проиллюстрировать, что они могут и не могут сделать.
Сначала давайте объясним некоторые понятия:
- Crawlable: могут ли поисковые системы сканировать URL?
- Индексируемый: поощряются ли поисковые системы индексировать URL?
- Предотвращает дублирование контента: предотвращает ли этот метод проблемы с дублированием контента ?
- Консолидация сигналов: поощряются ли поисковые системы к актуализации актуальности и Сигналы авторизации URL , как определено содержанием URL и ссылками?
Кроме того, важно понимать, что бюджет обхода является. Бюджет сканирования - это количество времени, которое сканеры поисковых систем проводят на вашем сайте. Вы хотите, чтобы они проводили это с умом, и вы можете дать им инструкции для этого.
Методы контроля сканирования и индексации
Robots.txt

файл robots.txt это центральное место, которое предоставляет основные правила для сканеров. Мы называем эти основные правила директивами . Если вы не хотите, чтобы сканеры сканировали определенные URL, ваш robots.txt - лучший способ сделать это.
Если сканерам не разрешено сканировать URL-адрес и запрашивать его содержимое, индексатор никогда не сможет анализировать его содержимое и ссылки. Это может предотвратить дублирование контента, а также означает, что рассматриваемый URL никогда не сможет ранжироваться. Кроме того, поисковые системы не смогут объединить актуальные сигналы релевантности и авторитета, когда они не знают, что находится на странице. Поэтому эти сигналы будут потеряны.
Конечная таблица на сканирование и индексирование
Часто ломая голову, какой метод использовать при управлении поисковыми системами? Сэкономьте время и выберите правильные методы!
Пример использования robots.txt
Раздел администратора сайта является хорошим примером того, где вы хотите применить файл robots.txt, чтобы сканеры не имели к нему доступа. Допустим, раздел администратора находится по адресу: https://www.example.com/admin/.
Запретить сканерам доступ к этому разделу с помощью следующей директивы в вашем файле robots.txt:
Disallow / admin
Не можете изменить файл robots.txt? Затем примените директива роботов noindex в раздел / admin.
Важные заметки
Обратите внимание, что URL-адреса, которые запрещены для сканирования поисковыми системами, могут по-прежнему появляться в результатах поиска. Это происходит, когда URL-адреса связаны с другими страницами или уже были известны поисковым системам до того, как они стали недоступными через robots.txt. Поисковые системы будут отображать фрагмент так:
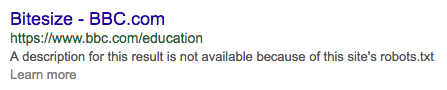
Robots.txt не может решить существующие проблемы с дублированным содержимым. Поисковые системы не забудут URL просто потому, что не могут получить к нему доступ.
Добавление канонического URL-адреса или атрибута noindex мета-роботов к URL-адресу, заблокированному через robots.txt, не приведет к его деиндексации. Поисковые системы никогда не узнают о вашем запросе на деиндексирование, потому что ваш файл robots.txt не позволяет им это узнать.
Файл robots.txt является важным инструментом оптимизации бюджета сканирования на вашем веб-сайте. Используя файл robots.txt, вы можете запретить поисковым системам сканировать те части вашего сайта, которые для них не важны.
Что будет делать файл robots.txt:
- Не позволяйте поисковым системам сканировать определенные части вашего веб-сайта, тем самым сохраняя бюджет сканирования.
- Не позволяйте поисковым системам индексировать определенные части вашего сайта, если на них нет ссылок.
- Предотвратить новые проблемы с дублированием контента.
Что файл robots.txt не будет делать:
- Консолидация релевантности и авторитетности сигналов.
- Удалить контент, который уже проиндексирован *.
* Хотя Google поддерживает директива noindex и удалит URL из своего индекса, не рекомендуется использовать этот метод, поскольку это неофициальный стандарт. Это поддерживается только Google и не 100% доказательство дурака. Используйте только тогда, когда вы не можете использовать директивы роботов а также канонические URL ,
Хотите узнать больше о robots.txt?
Проверьте окончательный robots.txt справочное руководство ,
Директивы роботов

Директивы роботов инструктируют поисковые системы о том, как индексировать страницы, сохраняя при этом доступность страницы для посетителей. Часто он используется, чтобы дать указание поисковым системам не индексировать определенные страницы. Когда дело доходит до индексации, это более сильный сигнал, чем канонический URL.
Реализация директив robots обычно выполняется путем включения их в исходный код с использованием мета-тега robots. Для других документов, таких как PDF или изображения, это делается через HTTP-заголовок X-Robots-Tag.
Пример использования директив роботов
Скажем, у вас есть десять целевых страниц для трафика Google AdWords. Вы скопировали контент с других страниц, а затем немного изменили его. Вы не хотите, чтобы эти целевые страницы были проиндексированы, потому что это может вызвать проблемы с дублированием контента, поэтому вы включаете директиву robots с атрибутом noindex.
Важные заметки
Директивы robots помогают предотвратить дублирование контента, но не приписывают актуальность и полномочия другому URL. Это просто потеряно.
Помимо указания поисковым системам не индексировать страницу, директивы роботов также не позволяют поисковым системам сканировать страницу. Из-за этого сохраняется некоторый бюджет обхода.
В отличие от его имени, атрибут nofollow директив robots не будет влиять на сканирование страницы, имеющей атрибут nofollow. Однако, когда установлен атрибут nofollow директив robots, поисковые роботы не будут использовать ссылки на этой странице для сканирования других страниц и впоследствии не будут передавать полномочия этим другим страницам.
Что будут делать директивы роботов:
- Не позволяйте поисковым системам индексировать определенные части вашего сайта.
- Предотвращение дублирования проблем с контентом.
Что директивы роботов не будут делать:
- Не позволяйте поисковым системам сканировать определенные части вашего веб-сайта, сохраняя бюджет сканирования.
- Консолидировать большую часть релевантных и авторитетных сигналов.
Хотите узнать больше о директивах роботов?
Проверьте окончательное руководство по мета теги роботов ,
Канонические URL

Канонический URL сообщает каноническую версию страницы поисковым системам, поощряя поисковые системы индексировать каноническую версию. Канонический URL может ссылаться на себя или на другие страницы. Если для посетителей полезно иметь доступ к нескольким версиям страницы, и вы хотите, чтобы поисковые системы рассматривали их как одну версию, канонический URL - это путь. Когда одна страница ссылается на другую страницу с использованием канонического URL-адреса, большая часть ее актуальности и авторитета связана с целевым URL-адресом.
Пример использования канонического URL
Скажем, у вас есть сайт электронной коммерции с продуктом в трех категориях. Продукт доступен через три разных URL. Это хорошо для посетителей, но поисковые системы должны сосредоточиться только на сканировании и индексации одного URL. Выберите одну из категорий в качестве основной и канонизируйте две другие категории.
Важные заметки
Убедитесь, что 301 перенаправляет URL-адреса, которые больше не служат цели для посетителей, в каноническую версию. Это позволяет вам приписать всю их актуальную актуальность и авторитет канонической версии. Это также помогает заставить другие веб-сайты ссылаться на каноническую версию.
Канонический URL - это скорее директива, а не директива. Поисковые системы могут игнорировать это.
Применение канонического URL-адреса не сохранит бюджет сканирования, поскольку это не мешает поисковым системам сканировать страницы. Это предотвращает их возвращение для поисковых запросов, поскольку они объединены в каноническую версию URL.
Что будет делать канонический URL:
- Не позволяйте поисковым системам индексировать определенные части вашего сайта.
- Предотвращение дублирования проблем с контентом.
- Консолидировать большую часть релевантных и авторитетных сигналов.
Что канонический URL не будет делать:
- Не позволяйте поисковым системам сканировать определенные части вашего веб-сайта, тем самым сохраняя бюджет сканирования.
Хотите узнать больше о канонических URL?
Проверьте окончательный канонический справочник URL ,
Атрибут Hreflang

Атрибут ссылки rel = «alternate» hreflang = «x», или атрибут hreflang для краткости, используется для связи с поисковыми системами, на каком языке ваш контент и для какого географического региона он предназначен. Если вы используете один и тот же контент или похожий контент для таргетинга на несколько регионов, hreflang - это то, что вам нужно. Это позволяет вам ранжировать ваши страницы на ваших рынках.
Это помогает предотвратить дублирование контента, поэтому наличие двух страниц с одинаковым содержанием для Соединенного Королевства и Соединенных Штатов - это хорошо, когда вы внедрили hreflang. Помимо дублированного контента, самое главное - убедиться, что ваш контент рифмуется с аудиторией. Убедитесь, что ваша аудитория чувствует себя как дома, поэтому рекомендуется иметь (несколько) различный текст и визуальные эффекты для Соединенного Королевства и Соединенных Штатов.
Пример использования hreflang
Вы ориентируетесь на несколько англоязычных рынков, используя субдомены для каждого рынка. Каждый поддомен содержит английский контент, локализованный для своего рынка:
- www.example.com для рынка США
- ca.example.com для канадского рынка
- uk.example.com для рынка Великобритании
- au.example.com для австралийского рынка
На каждом рынке вы хотите получить рейтинг с нужной страницей. Вот где приходит hreflang.
Что будет делать атрибут hreflang:
- Помогите поисковым системам оценить правильный контент на правильном рынке.
- Предотвращение дублирования проблем с контентом.
Что не сделает атрибут hreflang:
- Не позволяйте поисковым системам сканировать определенные части вашего веб-сайта, тем самым сохраняя бюджет сканирования.
- Не позволяйте поисковым системам индексировать определенные части вашего сайта.
- Консолидация релевантности и авторитетности сигналов.
Хотите узнать больше о hreflang?
Проверьте окончательный справочное руководство hreflang ,
Атрибуты пагинации

Атрибуты ссылок rel = «prev» и rel = «next», для краткости атрибуты пагинации , используются для передачи отношений между сериями страниц поисковым системам. Для ряда похожих страниц, таких как страницы архива блогов с разбивкой по страницам или страницы категорий продуктов с разбивкой по страницам, настоятельно рекомендуется использовать атрибуты разбивки на страницы. Поисковые системы поймут, что страницы очень похожи, что устранит проблемы с дублированием контента.
В большинстве случаев поисковые системы не будут ранжировать другие страницы, кроме первой в разбивке на страницы.
Что будут делать атрибуты пагинации:
- Предотвращение дублирования проблем с контентом.
- Консолидация релевантности и авторитетных сигналов.
Что атрибуты пагинации не будут делать:
- Не позволяйте поисковым системам сканировать определенные части вашего веб-сайта, тем самым сохраняя бюджет сканирования.
- Не позволяйте поисковым системам индексировать определенные части вашего сайта.
Хотите узнать больше об атрибутах нумерации страниц?
Проверьте окончательный справочник по нумерации страниц ,
Мобильный атрибут

Мобильный атрибут rel = «alternate» или, если коротко, мобильный атрибут , сообщает поисковым системам связь между настольной версией веб-сайта и мобильной версией. Это помогает поисковым системам показывать правильный веб-сайт для правильного устройства и предотвращает проблемы с дублирующимся контентом в процессе.
Что будет делать мобильный атрибут:
- Предотвращение дублирования проблем с контентом.
- Консолидация релевантности и авторитетных сигналов.
Что мобильный атрибут не будет делать:
- Не позволяйте поисковым системам сканировать определенные части вашего веб-сайта, тем самым сохраняя бюджет сканирования.
- Не позволяйте поисковым системам индексировать определенные части вашего сайта.
Хотите узнать больше о мобильном атрибуте?
Проверьте окончательный справочник по мобильным атрибутам ,

Если вы не можете вносить (быстро) изменения в свой веб-сайт, вы можете настроить обработку параметров в Google Search Console и Bing Webmaster Tools. Обработка параметров определяет, как поисковые системы должны обращаться с URL-адресами, содержащими параметр. Используя это, вы можете запретить Google и Bing сканировать и / или индексировать определенные URL-адреса.
Чтобы настроить обработку параметров, вам нужны URL, которые можно идентифицировать по шаблону. Обработка параметров должна использоваться только в определенных ситуациях, например, для сортировки, фильтрации, перевода и сохранения данных сеанса.
Важная заметка
Имейте в виду, что настройка этого для Google и Bing не повлияет на то, как другие поисковые системы сканируют ваш сайт.
Что будет делать обработка параметров:
- Не позволяйте поисковым системам сканировать определенные части вашего веб-сайта, тем самым сохраняя бюджет сканирования.
- Не позволяйте поисковым системам индексировать определенные части вашего сайта.
- Предотвращение дублирования проблем с контентом.
- Консолидация релевантности и авторитетных сигналов.
Что обработка параметров не будет делать:
- Позволяет настроить сканирование и индексацию для отдельных URL-адресов.

HTTP-аутентификация требует, чтобы пользователи или машины входили в систему, чтобы получить доступ к (разделу) веб-сайта. Вот пример того, как это выглядит:
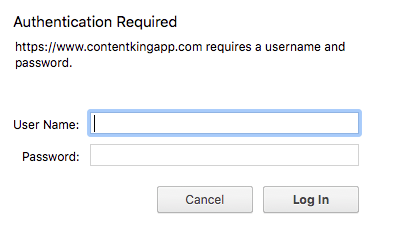
Без имени пользователя и пароля вы (или робот) не сможете пройти через экран входа в систему и не сможете получить доступ к чему-либо. HTTP-аутентификация - это отличный способ уберечь нежелательных посетителей - как людей, так и сканеры поисковых систем - от, например, тестовой среды. Google рекомендует использование HTTP-аутентификации для предотвращения доступа сканеров поисковых систем к тестовым средам:
Если у вас есть конфиденциальный или личный контент, который вы не хотите показывать в результатах поиска Google, самый простой и эффективный способ заблокировать появление частных URL-адресов - это сохранить их в защищенном паролем каталоге на сервере вашего сайта. Робот Google и другие веб-сканеры не могут получить доступ к содержимому в защищенных паролем каталогах.
Что будет делать аутентификация HTTP:
- Не позволяйте поисковым системам сканировать определенные части вашего веб-сайта, тем самым сохраняя бюджет сканирования.
- Не позволяйте поисковым системам индексировать определенные части вашего сайта.
- Предотвращение дублирования проблем с контентом.
Что HTTP-аутентификация не будет делать:
- Консолидация релевантности и авторитетных сигналов.
Конечная таблица на сканирование и индексирование
Быстро выберите правильный метод для решения проблем сканирования и индексации!
Получить в качестве поисковых систем: поставить себя на их место
Итак, как поисковые роботы видят ваши страницы и как они отображаются? Поставьте себя на их место, используя инструменты «Fetch and Render».
Функция Google «Получить как Googlebot» наиболее известна. Находится в консоли поиска Google и позволяет вам заполнить URL на вашем сайте, а затем Google покажет вам, что их сканеры видят по этому URL, и как они отображают URL. Вы можете сделать это как для настольных компьютеров, так и для мобильных устройств. Посмотрите ниже, как это выглядит:
Он отлично подходит для двойной проверки того, отвечают ли URL-адреса, как ожидается, но также для принудительной индексации URL-адреса («Индексация запросов»). В течение нескольких секунд вы можете сканировать и индексировать URL. Это не означает, что его содержимое немедленно обрабатывается и рейтинги корректируются, но это позволяет ускорить процесс сканирования и индексации.
Другие ситуации, в которых Fetch as Googlebot пригодится
Выбор Googlebot не только полезен для ускорения процесса сканирования и индексации отдельного URL, но и позволяет:
- Ускорьте открытие новых разделов на вашем сайте
Извлеките URL-адрес, с которого связаны новые разделы, и выберите «Запросить индекс» с параметром «Сканировать этот URL-адрес и его прямые ссылки». - Аудит мобильных пользователей на вашем сайте:
Получить URL-адрес как «Мобильный телефон: смартфон». - Проверьте, правильно ли работают 301-перенаправления.
Введите URL и проверьте ответ заголовка.
Заметки:
- Ситуация 3 может быть легче реализована, навалом внутри ContentKing.
- Google позволяет отправлять 500 URL-адресов в месяц для индексации.
- Google позволяет отправлять только 10 URL-адресов в месяц для индексации, при этом все URL-адреса, связанные с этим URL-адресом, также сканируются.
- Bing имеет аналогичный инструмент, который называется Получить как Bingbot ».
Часто задаваемые вопросы о сканировании и индексации
- Как часто Google сканирует мой сайт?
- Могу ли я замедлить сканеры, когда они сканируют мой сайт?
- Как запретить поисковым системам сканировать веб-сайт или страницу?
- Что означает индексация сайта?
- Является ли мой сайт индексируемым для поисковых систем?
- Как часто Google индексирует мой сайт?
- Сколько времени понадобится Google, чтобы проиндексировать мой новый веб-сайт?
- Как запретить поисковым системам индексировать сайт или страницу?
1. Как часто Google сканирует мой сайт?
Консоль поиска Google делится с вами своими правилами сканирования. Чтобы проверить это:
- Войдите в консоль поиска Google и выберите веб-сайт.
- Перейдите в раздел «Сканирование»> «Статистика сканирования» и там вы узнаете, как часто Google сканирует ваш сайт.
Если вы достаточно разбираетесь в технологиях, вы можете узнать, как часто Google сканирует ваш сайт, анализируя файлы журналов вашего сайта.
Стоит отметить, что Google определяет, как часто они должны сканировать ваш сайт, используя бюджет обхода для вашего сайта.
2. Могу ли я замедлить сканеры, когда они сканируют мой сайт?
Да, вы можете сделать это с помощью ползать задержки директива robots.txt. Google не будет слушать это все же. Если вы хотите, чтобы робот Googlebot сканировал медленнее, чем нужно настроить в консоли поиска Google. Независимо от метода не рекомендуется ограничивать сканеры Google и Bing. Их сканеры достаточно умны, чтобы знать, когда у вашего веб-сайта трудные времена, и они проверят позже в этом случае.
3. Как запретить поисковым системам сканировать веб-сайт или страницу?
Есть несколько способов запретить поисковым системам сканировать части вашего сайта или только определенные страницы:
- Robots.txt: может использоваться для предотвращения сканирования всего сайта, разделов и отдельных страниц.
- Обработка параметров: может использоваться для предотвращения сканирования URL-адресов, содержащих определенный параметр.
- HTTP-аутентификация: может использоваться для предотвращения сканирования всего сайта, разделов и отдельных страниц.
4. Что означает индексация сайта?
Это означает, что действия выполняются поисковой системой, чтобы понять веб-сайт и сделать его доступным через свою поисковую систему.
5. Является ли мой сайт индексируемым для поисковых систем?
Лучший способ ответить на это создать учетную запись с ContentKing оценить, насколько индексируем ваш сайт для поисковых систем. Как вы уже могли прочитать выше, есть много способов повлиять на то, как поисковые системы индексируют ваш сайт.
6. Как часто Google индексирует мой сайт?
Как часто Google сканирует ваш сайт. Его сканеры передают все, что они нашли, индексатору, который занимается индексацией сайтов.
7. Сколько времени понадобится Google, чтобы проиндексировать мой новый сайт?
На этот вопрос нет однозначного ответа, так как это зависит от продвижения нового сайта. Его продвижение ускоряет процесс сканирования и индексации. Если вы делаете это хорошо, небольшой сайт может быть проиндексирован за час. Кроме того, могут также потребоваться месяцы для индексации совершенно нового веб-сайта.
Обратите внимание, что индексирование вашего сайта поисковыми системами не означает, что ваши страницы начнут занимать высокие позиции сразу. Достижение высоких рейтингов занимает намного больше времени.
8. Как запретить поисковым системам индексировать сайт или страницу?
Поисковые системы могут быть защищены от индексации веб-сайта или страницы следующими способами:
- Meta Robots noindex tag: очень сильный сигнал для поисковых систем не индексировать страницу. Он не передает сигналы релевантности или авторитета другим страницам.
- Канонический URL: умеренно сильный сигнал для поисковых систем о том, какую страницу индексировать, а также приписывать релевантные и авторитетные сигналы.
- HTTP-аутентификация: только предотвратит сканирование и индексацию новых страниц с точки зрения SEO. Но все же в общем случае рекомендуется использовать проверку подлинности HTTP в тестовых средах, чтобы исключить нежелательные поисковые системы и пользователей.
- Robots.txt: можно использовать только для предотвращения сканирования и индексации новых страниц.
- Обработка параметров: может использоваться для предотвращения сканирования и индексации URL-адресов, содержащих определенный параметр.
Похожие
Позиционирование поисковых систем (SEO)... иционирование поисковых систем (SEO) Позиционирование поисковых систем (SEO) В настоящее время недостаточно иметь веб-страницу. Находиться в Интернете необходимо, но недостаточно для привлечения посетителей. Без серьезной работы по естественному Как сделать аудит сайта
Вы уже знаете, как важно время от времени проверять свои финансовые записи. Считаете ли вы, что аудит вашего сайта будет хорошей идеей? Цель состоит в том, чтобы определить, предоставляет ли сайт те преимущества, которые вы желаете, и, возможно, определить способы сделать его более эффективным. Хотя существует несколько подходов к проведению аудита такого типа, начните с этого базового плана. Помните, что вы всегда можете Создание сайтов на сайтах Google
Сайты Google - это один из многих инструментов, которые предлагает Google и которые мы можем создавать бесплатные сайты или блоги. Эта возможность делать сайты на платформе Google бесплатно существует уже довольно давно. Однако дизайн и даже простота управления созданными сайтами были не лучшими. Не так давно (2016) Google решила сделать большое « обновление » в приложении Сайтов Google, и теперь, да, это очень хорошо для того, что предназначено. Некоторые Мобильный телефон и SEO: Google удаляет URL-адреса из поисковых запросов?
... сайт все еще появляется (вверху над сообщением), в окружении значка AMP, размещенного в качестве доказательства в гораздо большей степени, чем в предыдущих представлениях. На данный момент изменения касаются только операционной системы Android. Удаляет ли Google URL-адреса из поисковых систем? Действительно ли Google удаляет URL-адреса из результатов поиска? Нет, это не совсем так: это более точное усовершенствование страниц AMP ( ускоренных мобильных страниц Google не индексирует мой сайт
... какие сайты они продают ссылки. Не покупайте обратные ссылки, дети. Просто сказать нет. Это всегда заканчивается слезами. Вам нужны обратные ссылки для SEO? Это не значит, что вам не нужны обратные ссылки. Ты сделаешь. Вот одна ситуация, где вы делаете. Старая подруга Ивонн Адель попросила меня взглянуть на этот сайт. Как твой SEO?
... и Это первая страница поиска «обновлений в Калгари», который я сделал (извините, их немного сложно прочитать, но нажмите на изображение, и оно появится в другом окне)"> Роб Коци Это первая страница поиска «обновлений в Калгари», который я сделал (извините, их немного сложно прочитать, но нажмите на изображение, и оно появится в другом окне). Это ты наверху страницы? Если вы не находитесь в этом снимке экрана, вы, вероятно, не получите звонок от домовладельца, Google Sandbox
Обмен - это забота! Частью алгоритма Google всегда было количество ссылок на сайт, и Google знает, что этой системой можно манипулировать с помощью ссылочного спама. За последние несколько лет Google изменил свой алгоритм, чтобы попытаться минимизировать такие манипуляции. Спам со ссылками происходит, когда новый веб-сайт получает много новых входящих ссылок с других сайтов, включая другие сайты, принадлежащие одному и тому же лицу. Если Google считает, что на Что такое SEO-копирайтинг?
SEO-копирайтинг - это механизм преобразования текста в текст для сайта, где текст создается по ключевым словам. Это, в свою очередь, помогает пользователям найти то, что они ищут в Интернете. Как Google Plus влияет на органическое позиционирование нашего сайта?
... сайта и многое другое. С момента появления Google Panda и Google Penguin наличие профиля в Facebook, Twiiter, Linkedin или Google plus считается необходимым для улучшения наших результатов в Google (его алгоритм учитывает социальные сети и еще 199 элементов). Из всех существующих социальных сетей было показано, что наличие профиля в Google Plus Google SEO Evolution
... как выглядел интерфейс. Так что этот аспект хорош, люди приспосабливаются и просто привыкают к нему. Я думаю, что все эти изменения, которые Google вносит, в конечном итоге приведут к улучшению поиска для пользователя и для SEO эксперты там. Вот письмо, Что такое SEO?
... имизация сайта - определение? Когда вы ищете Google , Yahoo или Бинг , вы вводите поисковый запрос в поле поиска. Искатель выкидывает результаты. Оптимизация сайта для поисковых систем означает принятие определенных мер, чтобы сайт оказался
Комментарии
Вы знаете, что хотите повысить рейтинг своего сайта в поисковых системах (SER), но знаете ли вы, с чего начать или как найти качественного SEO-консультанта или стратега?Вы знаете, что хотите повысить рейтинг своего сайта в поисковых системах (SER), но знаете ли вы, с чего начать или как найти качественного SEO-консультанта или стратега? Пока не вырывайте голову - я здесь, чтобы помочь вам понять SEO и дать несколько советов, когда вы будете готовы работать с SEO-компанией или консультантом. (Этот пост длинный, но, пожалуйста, оставайтесь со мной. Он сэкономит вам время и деньги.) Во-первых, что такое SEO? Знаете ли вы, что подавляющее большинство людей находят то, что ищут, с помощью поисковых систем (таких как Google, Yahoo и MSN)?
Знаете ли вы, что подавляющее большинство людей находят то, что ищут, с помощью поисковых систем (таких как Google, Yahoo и MSN)? Привлекайте трафик на ваш сайт и переводите его в доходы и прибыль для вашего бизнеса. У нас есть опыт, и мы можем заставить поисковые системы работать на вас! Вопрос: Чтобы избежать штрафа, предлагаете ли вы дезавуировать ссылки в свете обновления Google, когда они сказали, что будут игнорировать некачественные ссылки?
Вопрос: Чтобы избежать штрафа, предлагаете ли вы дезавуировать ссылки в свете обновления Google, когда они сказали, что будут игнорировать некачественные ссылки? Ответ. Отказ от нежелательных ссылок - это всегда хороший подход. Хотя Google может стремиться выявлять некачественные ссылки, их алгоритмы не всегда делают это правильно. Следовательно, нет смысла рисковать тем, что Google может или не может сбрасывать со счетов низкокачественные ссылки Вы еще не начали ссылаться на свой сайт или на Google Date, или вы думаете, что его SEO можно оптимизировать?
Вы еще не начали ссылаться на свой сайт или на Google Date, или вы думаете, что его SEO можно оптимизировать? У вас должен быть полный анализ, сделанный признанным профессионалом. Каждый аудит полностью настраивается. Это позволяет вам подвести итоги текущего статуса ссылки на ваш сайт, но особенно перечислить все области для улучшения. Поэтому я предоставляю подробный отчет о практических рекомендациях, касающихся как самого сайта, так и его видимости в Интернете, его репутации и конкурентов. Таким образом, вместо того, чтобы задавать вопрос «является ли это оптимизированным для SEO», задайте себе вопрос «Является ли эта публикация работы настолько четкой и подробной, как и должно быть?
Таким образом, вместо того, чтобы задавать вопрос «является ли это оптимизированным для SEO», задайте себе вопрос «Является ли эта публикация работы настолько четкой и подробной, как и должно быть?» Если ответ «да», то поисковые системы будут вознаграждать вас. Чтобы получать такие сообщения в блоге прямо в свой почтовый ящик, Если это число не соответствует вашим ожиданиям, задайте себе несколько вопросов: часто ли они сканируют мой сайт?
Если это число не соответствует вашим ожиданиям, задайте себе несколько вопросов: часто ли они сканируют мой сайт? Я не обновляю свой сайт? Это все быстрые вещи, которые вы можете увидеть прямо на панели инструментов, и вы даже можете посмотреть на ключевые слова поиска, чтобы увидеть, как люди находят вас. Быстрый факт: Bing не использует Google Analytics. 2. Диагностические инструменты Категория диагностических инструментов состоит из Итак, теперь, когда мы установили важность проверок и как они резко увеличивают количество кликов, которые получает ваш список, как вы можете их получить?
Итак, теперь, когда мы установили важность проверок и как они резко увеличивают количество кликов, которые получает ваш список, как вы можете их получить? Создание надежного процесса проверки Во-первых, вам нужно, чтобы пользователи могли легко оставить вам отзыв. Google может сделать это немного сложным, поэтому мы создали обзор генератора ссылок , Введите свои данные, и вы получите ссылку Могу ли я (или буду ли я) полагаться на SEO для привлечения трафика на мой сайт?
Могу ли я (или буду ли я) полагаться на SEO для привлечения трафика на мой сайт? Является ли страница с параллаксом, состоящая в браке с другими соответствующими веб-страницами (комбинированный подход), вариантом? Если вы определитесь с комбо-подходом, то следует рассмотреть, какая информация является наиболее подходящей на странице параллакса по сравнению с другими страницами поддержки сайта. Некоторые ключевые моменты, которые следует помнить о том, как разделить информацию Исследуя привычки аудитории вашего клиента в социальных сетях и на форумах, видели ли вы их часто задающими вопросы, на которые ваш сайт должен давать ответы, но не так ли?
Исследуя привычки аудитории вашего клиента в социальных сетях и на форумах, видели ли вы их часто задающими вопросы, на которые ваш сайт должен давать ответы, но не так ли? Тщательно проанализировав существующий контент клиента, вы должны решить, что полностью удалить, что можно повторно использовать или улучшить, и какие темы им нужно начать обращать внимание, если они хотят сохранить интерес своей аудитории и сверстников. Сколько стоит потратить 100 евро в месяц, платя компании, которая не получает результатов, или, что еще хуже, получает штрафы Google для вашего сайта за выполнение методов, запрещенных Google?
Сколько стоит потратить 100 евро в месяц, платя компании, которая не получает результатов, или, что еще хуже, получает штрафы Google для вашего сайта за выполнение методов, запрещенных Google? Я работаю над этим более 12 лет : работаю как внештатный консультант, а также как SEO агентство на TREI.es , И по своему опыту я могу сказать вам, что не существует SEO "Low Cost" . Это так просто: Например, поисковая система обнаруживает страницу со словом «Apple», как она различает, является ли Apple фруктом или Apple брендом?
Например, поисковая система обнаруживает страницу со словом «Apple», как она различает, является ли Apple фруктом или Apple брендом? Он использует скрытые ключевые слова семантической индексации, если в статье есть такие слова, как фрукты, вкус, вкус, тогда поисковой системе будет легко определить, что статья посвящена «яблочным фруктам». Следовательно, в этом примере фрукт, вкус и аромат можно назвать ключевыми словами LSI для ключевого слова «Apple». Ключевые слова LSI набирают все большую популярность.
Как работает индексирование?
2. Могу ли я замедлить сканеры, когда они сканируют мой сайт?
3. Как запретить поисковым системам сканировать веб-сайт или страницу?
4. Что означает индексация сайта?
5. Является ли мой сайт индексируемым для поисковых систем?
6. Как часто Google индексирует мой сайт?
7. Сколько времени понадобится Google, чтобы проиндексировать мой новый сайт?
8. Как запретить поисковым системам индексировать сайт или страницу?
Есть много способов сделать это, поэтому когда использовать какой метод?
Итак, как вы контролируете весь этот процесс и повышаете свой рейтинг?